Aujourd’hui, on va parler d’un truc qui s’appelle LSD, mais attention hein, je parle pas de votre dernière soirée chemsex hein… C’est plutôt un clone open-source de la commande ls en mode survitaminé ! Développé par la communauté et écrit en Rust, il rajoute plein de fonctionnalités hyper stylées comme les couleurs, les icônes, la vue en arbre, des options de formatage en pagaille…
L’idée vient du projet colorls qui est vraiment super aussi. Mais LSD pousse le délire encore plus loin. Déjà il est compatible avec quasi tous les OS : Linux, macOS, Windows, BSD, Android…
Et hyper simple à installer en plus… un petit
apt install lsd ou brew install lsd
et c’est réglé.
Ensuite il est ultra personnalisable. Vous pouvez faire votre thème de couleurs et d’icônes sur mesure juste en bidouillant des fichiers de config en yaml. Et il supporte les polices Nerd Font avec des glyphes spéciaux trop classes ! Bon faut avoir la bonne police installée sur son système et le terminal configuré, mais c’est pas bien compliqué. Et si vous êtes sur Putty ou Kitty, y’a des tweaks spécifiques à faire, mais c’est expliqué dans la doc.
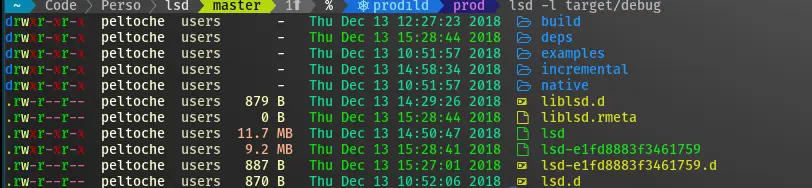
Mais attendez c’est pas fini ! LSD gère aussi les liens symboliques, la récursion dans les sous-répertoires (avec une profondeur max en option), des raccourcis pour les tailles de fichiers plus lisibles, des indicateurs pour les exécutables, les dossiers, etc. Il peut même vous sortir des infos de git sur les fichiers de ton repo si vous activez l’option ! Et pleins d’autres trucs que j’ai même pas encore testés…
Depuis que je l’ai installé et que j’ai changé mon alias ls, je me régale à chaque fois que je liste un dossier. J’ai l’impression d’être dans un vaisseau spatial avec des néons partout ! Bon j’exagère à peine, mais franchement ça envoie du lourd.
Allez je vais pas tout vous spoiler non plus, je vous laisse le plaisir de découvrir LSD par vous-même et customiser votre expérience du terminal. Moi en tout cas je suis fan, et je dis pas ça parce que je plane ! 😄
Thx Lorenper pour l’outil !